어텐션 (기계 학습)
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
어텐션(Attention)은 기계 학습 분야에서 입력 시퀀스의 각 요소에 가중치를 동적으로 부여하여 출력 시퀀스를 생성하는 메커니즘이다. 이는 시퀀스-투-시퀀스(seq2seq) 모델에서 장거리 의존성을 고려하고, 임의 길이의 입력을 처리하며, 병렬 처리를 가능하게 하여 기계 번역, 이미지 인식, 음성 합성 등 다양한 작업에 활용된다. 어텐션은 쿼리-키-값(Query-Key-Value, QKV) 모델로 설명되며, 쿼리와 키의 유사도에 따라 값에 가중치를 부여하는 방식으로 작동한다. 어텐션 메커니즘은 다양한 변형이 존재하며, 트랜스포머(Transformer)와 같은 모델의 핵심 구성 요소로 사용된다.

더 읽어볼만한 페이지
2. 역사
어텐션 메커니즘의 역사에 대한 학술적 검토는 Niu et al.[1] 및 Soydaner에서 제공된다.[2]
어텐션은 다음 역할을 수행하는 모듈로 설계되었다.
- seq2seq: 입력 벡터 열을 출력 벡터 열로 변환한다.[54]
- 장거리 의존성 고려: 인덱스 가 떨어진 입출력을 연결한다.[55]
- 임의 길이 벡터 열 변환: 추론마다 다른 길이의 입력 열을 처리한다.[56]
- 높은 병렬 처리 능력: 학습·추론의 고속화.[57]
예를 들어 기계 번역을 생각해 보자. 기계 번역 작업에서는 단어의 단순한 치환(일→영)으로는 목적을 달성할 수 없다. 왜냐하면 일본어와 영어의 어순이 다르기 때문이다. 즉, 입력 단어 벡터 열을 출력 단어 벡터 열로 변환할 때, 열을 열로 변환할 필요가 있다(''seq2seq''[58]). 또한 열 내의 가까운 부분만 참조하는 것으로는 불충분한 경우가 있다. 예를 들어 의문문의 일영 번역에서, 문두의 "Do" ()를 생성하기 위해서는 일본어 원문의 문말 "か?(か?)"()를 참조할 필요가 있다. 즉, 장거리 의존성을 고려할 수 있어야 한다. 또한 문장 길이는 일정하지 않으므로, 임의 길이의 입력을 다룰 수 있어야 한다.[59] 그리고 긴 벡터 열을 거대한 모델로 실무적으로 학습하기 위해서는 높은 병렬 처리 능력이 요구된다.
예를 들어 피드 포워드 모듈은 시간 방향의 가중치에 의해 seq2seq에 이용할 수 있지만, 가중치가 일정 수이므로 임의 길이 벡터 열을 다룰 수 없다. 합성곱 모듈은 임의 길이의 seq2seq에 이용할 수 있지만, 장거리 의존성을 다루기 위해서는 거대한 커널 또는 많은 층이 필요하다.[60] 순환 모듈은 3가지 요건을 이론상으로는 충족할 수 있지만, 단계별 회귀 과정에서 장기 의존 정보가 손실되는 것이 실무적으로 알려져 있다(참고: RNN#Copyingタスク)[61]。
이러한 요건은 기계 번역을 포함하는 자연어 처리뿐만 아니라, 이미지 내의 떨어진 위치에 있는 대상을 참조하고 싶은 이미지 인식이나, 음고의 시간적인 변동을 파악하고 싶은 음성 합성 등, 폭넓은 작업에서 요구되고 있다. 이러한 배경에서 "임의 길이의 열을 열로 변환할 때, 각 위치의 입력을 직접 가져오는 모듈"로서 제안·활용되고 있는 것이 어텐션 기구이다.
2. 1. 전조
인간의 선택적 주의력은 신경과학과 인지 심리학에서 잘 연구되어 왔다.[3] 1953년, 콜린 체리는 청각의 맥락에서 선택적 주의력을 연구했으며, 이는 칵테일 파티 효과로 알려져 있다.[4] 1958년, 도널드 브로드벤트는 주의력 필터 모델을 제안했다.[5] 시각의 선택적 주의력은 1960년대 조지 스펄링의 부분 보고 패러다임에 의해 연구되었다. 또한 안구 운동 제어가 인지 과정에 의해 조절된다는 사실이 발견되었으며, 이는 눈이 높은 두드러짐 영역을 선호하여 움직이기 때문이다. 눈의 중심와는 작기 때문에 눈은 한 번에 전체 시야를 선명하게 해상할 수 없다. 안구 운동 제어를 사용하면 눈이 장면의 중요한 특징을 빠르게 스캔할 수 있다.[6]이러한 연구 개발은 신경인지론과 그 변형과 같은 알고리즘에 영감을 주었다.[7][8] 한편, 신경망의 발전은 생물학적 시각적 주의력의 회로 모델에 영감을 주었다.[9][2] 예를 들어, 1998년에 발표된 잘 인용된 네트워크는 원숭이의 하위 수준 시각 시스템에서 영감을 받았다. 이 네트워크는 수작업으로 제작된(학습되지 않은) 특징을 사용하여 이미지의 두드러짐 맵을 생성했으며, 이 맵은 두 번째 신경망이 두드러짐을 줄이는 순서로 이미지의 패치를 처리하는 데 사용되었다.[10]
2. 2. 순환 어텐션 (Recurrent Attention)
딥러닝 시대에 어텐션 메커니즘은 인코딩-디코딩에서 유사한 문제를 해결하기 위해 개발되었다.[1]2014년에 제안된 seq2seq 모델[21]은 기계 번역에서 입력 텍스트를 고정 길이 벡터로 인코딩한 다음, 이를 출력 텍스트로 디코딩한다. 입력 텍스트가 긴 경우, 고정 길이 벡터는 정확한 디코딩을 위한 충분한 정보를 전달할 수 없었다.
2015년에 제안된 이미지 캡셔닝 모델은 seq2seq 모델에서 영감을 받았으며,[22] 입력 이미지를 고정 길이 벡터로 인코딩하고, seq2seq 모델에서 사용된 어텐션 메커니즘을 이미지 캡셔닝에 적용했다.[23][24]
2. 3. 트랜스포머 (Transformer)
시퀀스-투-시퀀스(seq2seq) 모델은 순환 신경망(RNN)을 사용하는데, 인코더와 디코더 모두 시퀀스를 토큰별로 처리해야 하므로 병렬 처리가 불가능하다는 단점이 있었다.[46] ''분해 가능한 어텐션''(Decomposable attention)은 입력을 병렬로 처리한 다음 "소프트 정렬 행렬"을 계산하여 이 문제를 해결하려 시도했다.[46][24]셀프 어텐션(Self-attention)은 입력 시퀀스를 인코딩할 때 LSTM이 메모리 네트워크로 보강되는 ''내부 어텐션''(internal attention)으로 제안되었다.[26]
이러한 흐름은 2017년 논문 ''Attention Is All You Need''에 발표된 트랜스포머 아키텍처에서 결합되었다.
3. 개념
어텐션은 "입력 벡터 열의 쿼리 의존적 동적 가중 합"에 해당하는 연산이다. 어텐션 메커니즘은 입력 시퀀스의 각 요소에 대한 가중치를 동적으로 계산하여, 출력 시퀀스를 생성할 때 각 요소의 중요도를 반영한다.
어텐션에서는 각 입력 벡터 의 가중 합을 번째 출력 벡터 로 한다. 이때, 가중치는 단순한 고정값이 아니라 동적으로 계산된다 ('''소프트 웨이트'''). 동적 계산은 번째 출력에 연결된 정보를 표현한 관련 벡터 와 입력된 입력 벡터 자체에 기반한다. 정보의 흐름을 표현하는 개념식은 다음과 같다.
:
이 식이 나타내는 것처럼, 어텐션에서는 각 출력에 대해 관련 벡터와 입력 벡터로부터 가중치를 구하고, 그 가중치에 기반하여 전체 입력을 받아들인다. 이를 통해 입력 열 전체를 각 출력 벡터에 직접 받아들이면서, 가중치의 동적 계산을 통해 임의 길이의 벡터 열을 처리할 수 있다. 즉, "임의 길이의 열을 열로 변환할 때, 각 위치의 입력을 직접 받아들이는 모듈"로 기능한다.
이 어텐션은 다른 관점에서 다시 볼 수 있다[62]。 어텐션에서는 입력 를 기반으로, 더해지는 값 ('''밸류''')와 이를 요약한 식별자 ('''키''')를 준비한다. 또한 각 출력에 연결된 관련 정보를 기반으로 쿼리 벡터 ('''쿼리''')를 준비하고, 쿼리와 키의 일치도에 따라 밸류의 가중치 = 받아들이는 양을 결정한다고 볼 수 있다[63]。 즉, 다음 개념식에 해당한다[62]:
:
첫 번째 개념식과 거의 유사한 형태이지만, 입력을 밸류로 변환한 다음 합을 취할 수 있는 유연성이 추가되었다. 각 입력 요소에 대한 가중치는 쿼리(query), 키(key), 값(value) 벡터 간의 상호작용을 통해 계산된다.
이 개념을 실제로 기능하는 연산으로 만들기 위해, 다음과 같은 구체화를 수행한다. 먼저, 의 크기에 제한이 없으면 무한 길이의 입력 열에 대해 출력 벡터가 발산해 버리므로, 소프트 웨이트는 비음수이며 출력 벡터마다 총합이 1 ()의 제약이 부과된다. 이 제약 내에서 쿼리와 키의 일치도를 측정하는 함수 (쿼리・키 메커니즘, query-key mechanism영어)를 구체적으로 정의하지만, 여기에는 다양한 변형이 존재한다. 내적 에 소프트맥스 함수를 적용한 형태가 대표적인 예이다[64]。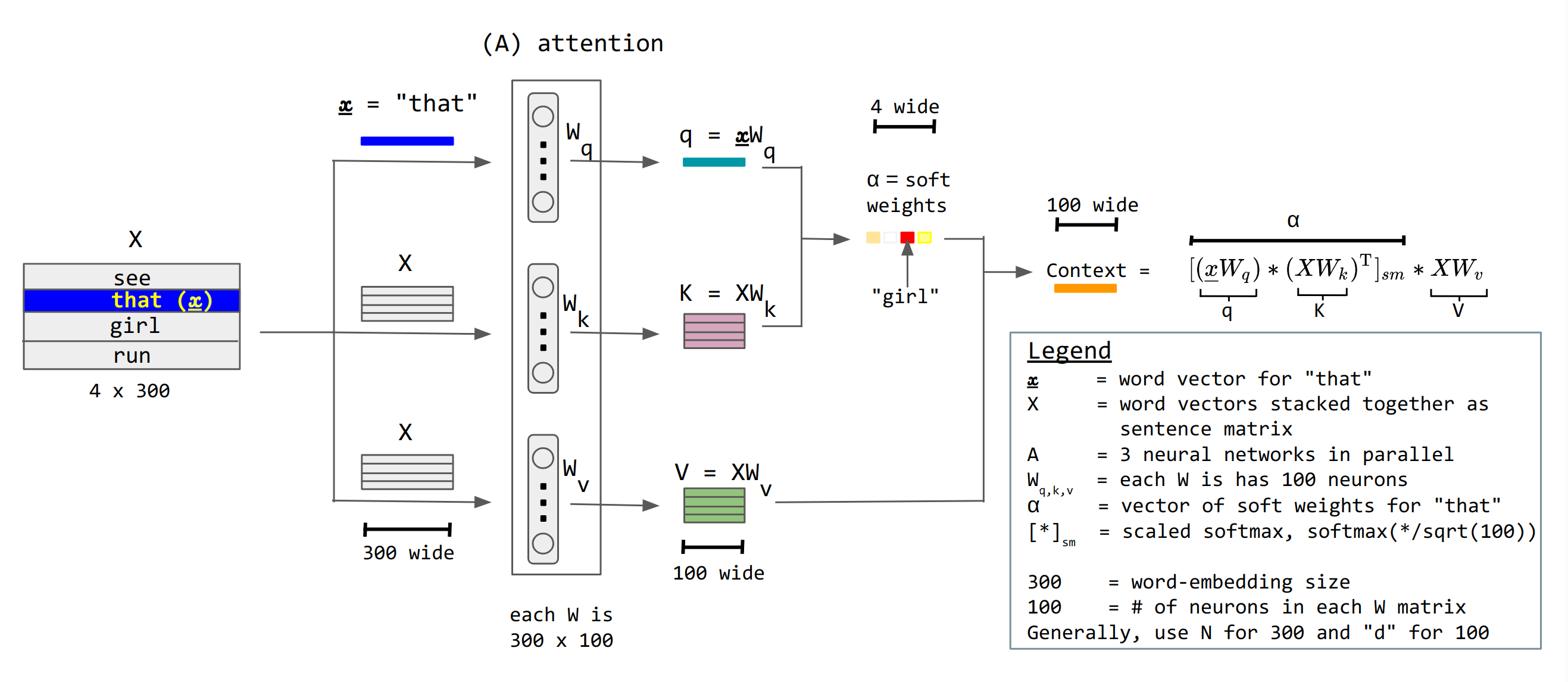
이 어텐션 방식은 관계형 데이터베이스의 질의-키(Query-Key) 비유에 비견되어 왔다. 이러한 비유는 질의 벡터와 키 벡터 사이에 '''비대칭적인''' 역할을 암시하는데, 여기서 '''하나'''의 관심 항목(질의 벡터 "that")이 '''모든''' 가능한 항목(문장 내 각 단어의 키 벡터)과 일치한다. 그러나 어텐션의 병렬 계산은 문장의 모든 단어를 자기 자신과 일치시키므로 이러한 벡터의 역할은 '''대칭적'''이다. 단순한 데이터베이스 비유가 결함이 있기 때문인지, 맥락 학습,[48] 마스크된 언어 작업,[49] 단순화된 트랜스포머,[50] 바이그램 통계,[33] N-gram 통계,[51] 쌍별 컨볼루션,[53] 및 산술 인수분해[52]와 같은 집중된 설정에서 어텐션의 역할을 연구함으로써 어텐션을 더 깊이 이해하려는 노력이 많이 이루어졌다.
3. 1. 쿼리-키-값 모델 (Query-Key-Value Model)
어텐션 메커니즘은 쿼리-키-값 모델로 설명될 수 있다.[48][49][50][33][51][53][52] 디코더는 쿼리를 보내고, 값의 가중 합계 형태의 응답을 얻는다. 여기서 가중치는 쿼리가 각 키와 얼마나 유사한지에 비례한다.[62]
데이터베이스 쿼리 언어에 비유하면, 모델은 키, 쿼리, 값의 세 가지 벡터를 구성한다. 디코더는 쿼리를 보내고 값의 가중 합계 형태의 응답을 얻으며, 여기서 가중치는 쿼리가 각 키와 얼마나 유사한지에 비례한다.
디코더는 먼저 "
쿼리와 키는 내적을 취하여 비교한다: . 이 내적 값들에 소프트맥스 함수를 적용하여 어텐션 가중치를 얻는다: .
이 가중치를 사용하여 컨텍스트 벡터를 계산한다:
여기서 는 값 벡터이며, 모델이 값을 표현하는 가장 좋은 방법을 찾을 수 있도록 다른 행렬에 의해 선형 변환된다.
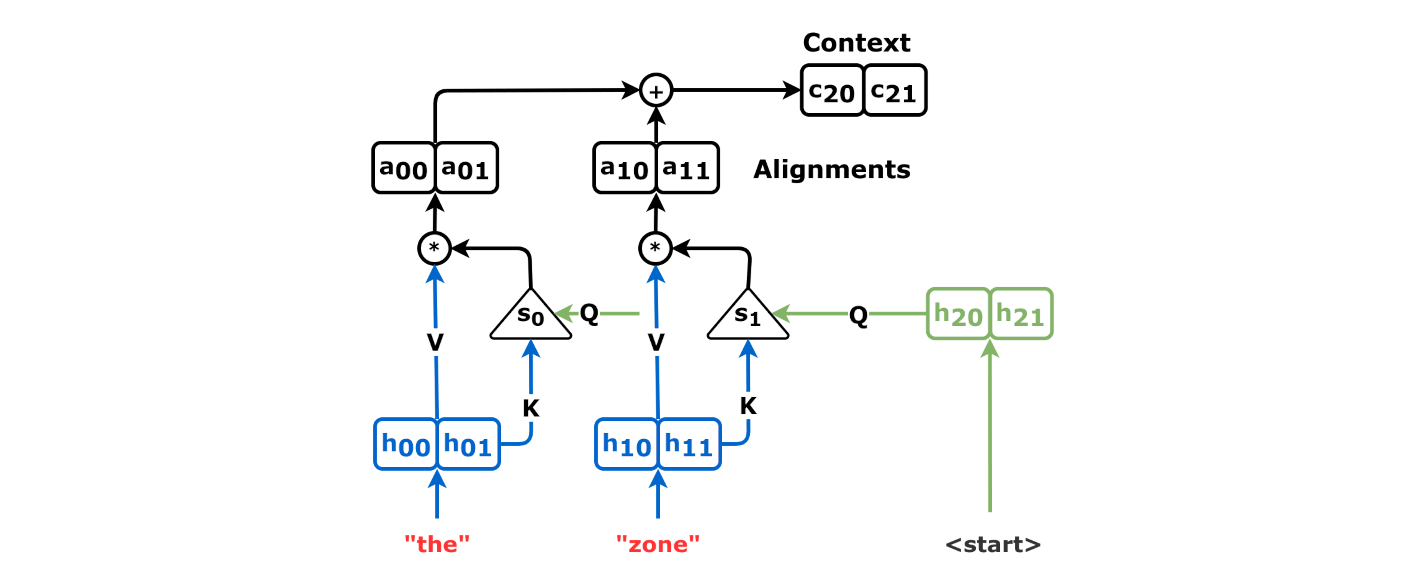
이것이 내적 어텐션 메커니즘이다. 이 섹션에서 설명된 특정 버전은 "디코더 교차 어텐션"인데, 출력 컨텍스트 벡터는 디코더에 의해 사용되고, 입력 키와 값은 인코더에서 가져오지만 쿼리는 디코더에서 가져오므로 "교차 어텐션"이다.
더 간결하게 다음과 같이 쓸 수 있다.
어텐션은 "입력 벡터 열의 쿼리 의존적 동적 가중 합"에 해당하는 연산이다. 각 입력 벡터 의 가중 합을 번째 출력 벡터 로 한다. 이때 가중치는 단순한 고정값이 아니라 동적으로 계산된다 (소프트 웨이트).
어텐션에서는 입력 를 기반으로, 더해지는 값 (밸류)와 이를 요약한 식별자 (키)를 준비한다. 또한 각 출력에 연결된 관련 정보를 기반으로 쿼리 벡터 (쿼리)를 준비하고, 쿼리와 키의 일치도에 따라 밸류의 가중치 = 받아들이는 양을 결정한다.[63]
소프트 웨이트는 비음수이며 출력 벡터마다 총합이 1 ()의 제약이 부과된다. 쿼리와 키의 일치도를 측정하는 함수는 쿼리・키 메커니즘(query-key mechanism영어)이라고 부르며, 내적 에 소프트맥스 함수를 적용한 형태가 대표적인 예이다.[64]
4. 언어 번역에서의 어텐션
어텐션 메커니즘은 기계 번역에서 특히 중요한 역할을 한다. 인코더-디코더 모델에서 어텐션은 디코더가 출력 단어를 생성할 때 입력 시퀀스의 어느 부분에 집중해야 하는지를 결정하는 데 사용된다.
영어를 프랑스어로 번역하는 기계를 구축하려면 기본적인 인코더-디코더에 어텐션 유닛(attention unit)을 합체한다. 가장 단순한 예에서 어텐션 유닛은 회귀 인코더 상태의 내적(dot product)으로 구성되며 훈련이 필요 없다. 실제로는 어텐션 유닛은 쿼리-키-값(query-key-value)이라고 불리는 3개의 완전 연결된 신경망 층으로 구성되며 훈련이 필요하다.

행렬로 보면 어텐션 가중치는 네트워크가 문맥에 따라 어떻게 어텐션을 조정하는지 보여준다.
이러한 어텐션 가중치의 생각은 신경망이 비판받는 '설명 가능성' 문제를 해결한다. 단어의 순서와 관계없이 일괄 번역(verbatim translation)을 수행하는 네트워크는 이러한 관점에서 분석 가능하다면 대각 지배 행렬을 갖게 된다. 반면 비대각 지배적인 경우, 어텐션 메커니즘이 더 미묘하다는 것을 보여준다. 디코더를 처음 통과했을 때 94%의 어텐션 가중치가 첫 번째 영어 단어 "I"에 걸려 있으므로 네트워크는 "je"라는 단어를 제시한다. 디코더의 두 번째 통과에서는 세 번째 영어 단어 "you"에 88%의 어텐션 가중치가 걸려 있으므로 "t'"를 제시한다. 마지막 통과에서는 두 번째 영어 단어 "love"에 95%의 어텐션 가중치가 걸려 있으므로 "aime"를 제시한다.
4. 1. 인코더-디코더 모델 (Encoder-Decoder Model)
인코더-디코더 모델은 2010년대 초에 개발된 시퀀스-투-시퀀스(Sequence-to-Sequence) 방법으로, 두 개의 신경망을 사용한다. 인코더는 입력 문장을 수치 벡터로 변환하고, 디코더는 해당 벡터를 대상 언어의 문장으로 변환한다. 어텐션 메커니즘은 2014년에 이 구조에 추가되었다.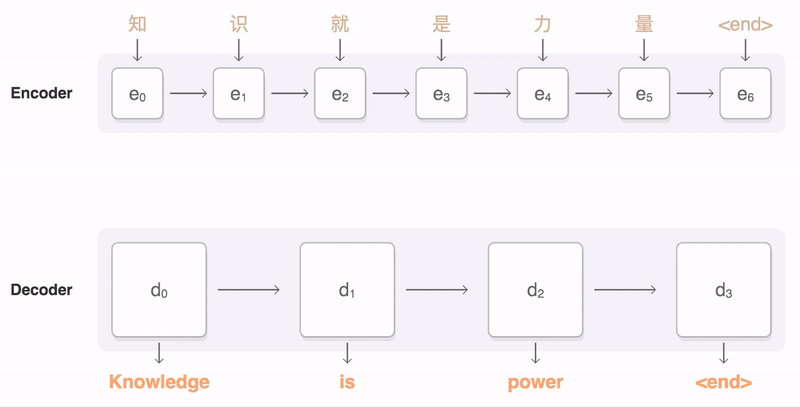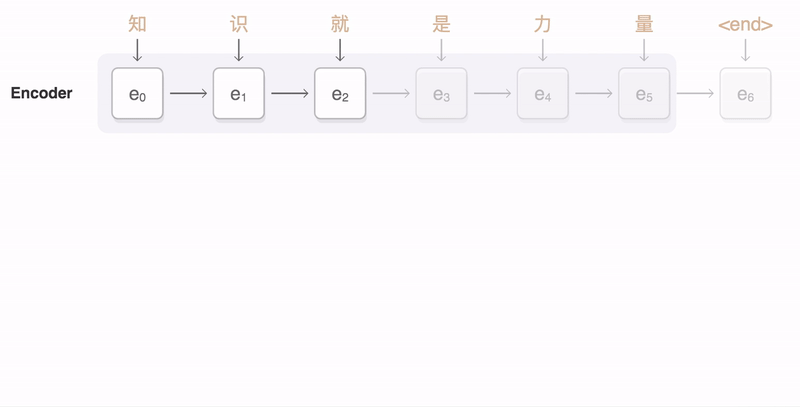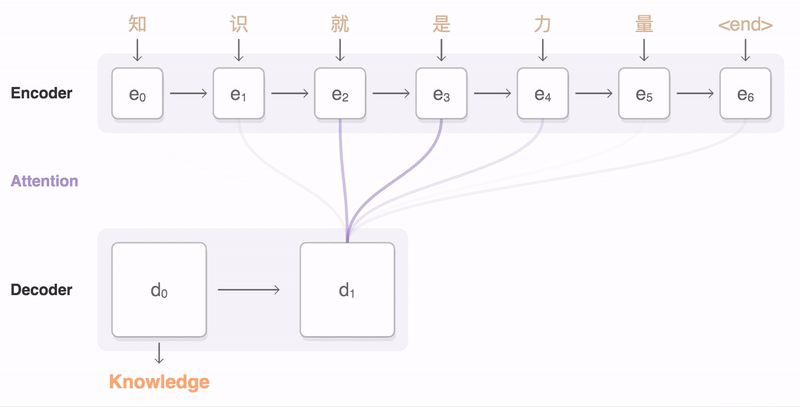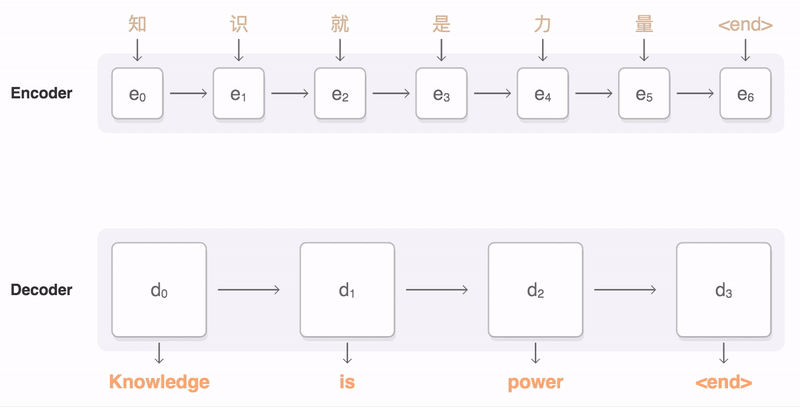
예를 들어, 영어-프랑스어 번역 작업에서 "the zone of international control
입력 시퀀스 는 신경망(LSTM, 트랜스포머 인코더 등)에 의해 실수 값 벡터 시퀀스 로 처리된다. 여기서 는 "은닉 벡터"를 의미한다.
인코더가 처리를 완료하면, 디코더는 은닉 벡터와 이전에 생성한 출력을 바탕으로 자기 회귀적으로 출력 시퀀스 를 생성한다. 즉, 다음 출력 단어를 생성하기 위해 인코더에서 생성된 은닉 벡터와 디코더 자신이 이전에 생성한 것을 모두 입력으로 받는다.
# (, "
# (, "
# (, "
# ...
# (, "
여기서 특수 토큰 `
영어를 프랑스어로 번역하는 기계를 구축하기 위해 기본적인 인코더-디코더에 어텐션 유닛(attention unit)을 합체한다. 가장 단순한 예에서 어텐션 유닛은 회귀 인코더 상태의 내적(dot product)으로 구성되며 훈련이 필요 없다.
어텐션 가중치는 신경망이 문맥에 따라 어떻게 어텐션을 조정하는지 보여준다. 예를 들어, "I love you"를 프랑스어로 번역하는 과정에서, 디코더는 각 단계를 생성할 때 입력 시퀀스의 특정 단어에 더 많은 가중치를 부여한다. 첫 번째 단계에서는 "I"에 94%의 가중치를 부여하여 "je"를 생성하고, 두 번째 단계에서는 "you"에 88%의 가중치를 부여하여 "t'"를 생성하며, 마지막 단계에서는 "love"에 95%의 가중치를 부여하여 "aime"를 생성한다.
4. 2. 정렬 (Alignment)
언어 간 번역에서 정렬은 소스 문장의 단어를 번역된 문장의 단어와 일치시키는 과정이다. 예를 들어 "I love you"라는 영어 문장을 프랑스어로 번역할 때, "love"는 "aime"와 정렬된다. 이러한 정렬 관계는 정렬 행렬로 표현될 수 있다.
위 표에서 볼 수 있듯이, 각 단어 쌍에 대한 정렬 강도를 나타내는 "소프트" 어텐션 가중치가 사용된다. 이는 "하드" 어텐션 가중치(하나의 어텐션 가중치를 1로 설정하고 나머지를 0으로 설정)보다 더 나은 성능을 보이는데, 모델이 "최고의 숨겨진 벡터"가 없을 수 있으므로 "최고의 것"이 아닌 숨겨진 벡터의 가중 합으로 구성된 컨텍스트 벡터를 만들기 때문이다.
어텐션 가중치는 신경망의 설명 가능성 문제를 해결하는 데 도움을 준다. 단어 순서에 관계없이 번역을 수행하는 네트워크는 행렬의 대각선을 따라 가장 높은 점수를 표시하는 반면, 비대각선 지배는 어텐션 메커니즘이 더 미묘하게 작동함을 보여준다. 예를 들어, 디코더의 첫 번째 통과에서 어텐션 가중치의 94%가 첫 번째 영어 단어 "I"에 있으므로 네트워크는 "je"를 출력하고, 두 번째 통과에서는 세 번째 영어 단어 "you"에 88%의 가중치가 있어 "t'"를, 마지막 통과에서는 두 번째 영어 단어 "love"에 95%의 가중치가 있어 "aime"를 출력한다.
어텐션 메커니즘은 인코더-디코더 모델에 통합되어 번역 성능을 향상시킨다. 어텐션 유닛은 일반적으로 쿼리-키-값(query-key-value)이라고 불리는 세 개의 완전 연결된 신경망 층으로 구성되며 훈련을 통해 학습된다.
5. 어텐션의 변형
어텐션 메커니즘은 다양한 변형이 존재한다.
- 고속 가중치 프로그래머 또는 고속 가중치 컨트롤러(1992).[31] "느린" 신경망은 다른 신경망의 "고속" 가중치를 외적을 통해 출력한다. 느린 네트워크는 기울기 하강을 통해 학습한다. 이후 "선형 셀프 어텐션"으로 이름이 변경되었다.[32]
- Bahdanau attention영어.[41] ''가산 어텐션''이라고도 함.
- Luong attention영어.[36] ''곱셈 어텐션''이라고 알려져 있음.
- 2016년에 ''분해 가능한 어텐션''으로 소개되었고 1년 후 트랜스포머에서 성공적으로 사용된 고도로 병렬화 가능한 ''셀프 어텐션''.
- ''위치 어텐션'' 및 ''인자화된 위치 어텐션''.[47]
합성곱 신경망의 경우 어텐션 메커니즘은 작동하는 차원에 따라 공간 어텐션,[45] 채널 어텐션,[44] 또는 조합으로 구분할 수 있다.[42][43]
맥락 내 학습,[48] 마스크된 언어 작업,[49] 단순화된 트랜스포머,[50] 바이그램 통계,[33] N-그램 통계,[51] 쌍별 컨볼루션,[53] 및 산술 인수분해[52]와 같은 집중된 설정에서 어텐션의 역할을 연구하여 어텐션을 더 깊이 이해하기 위해 많은 노력을 기울였다.
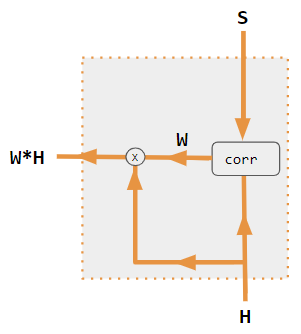
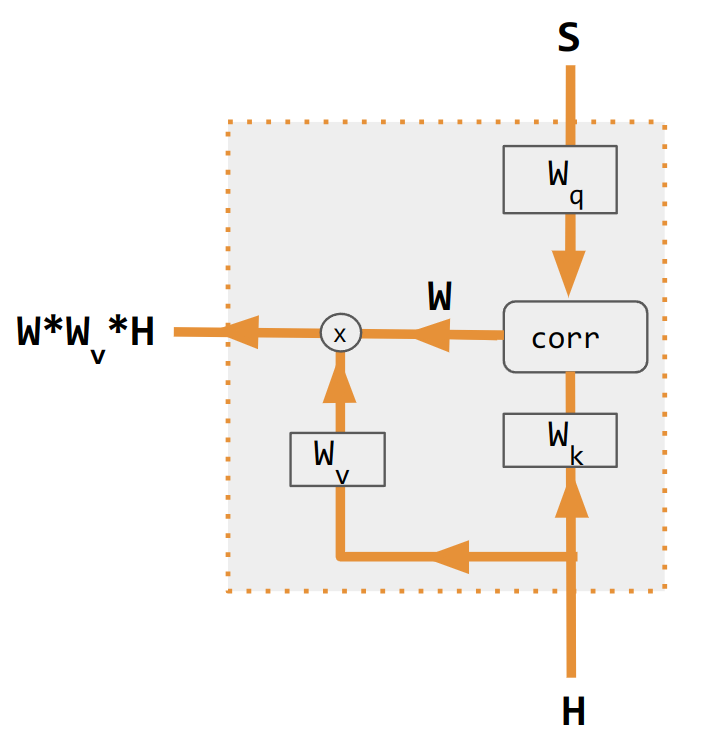
이러한 변형은 인코더 측 입력을 재조합하여 해당 효과를 각 대상 출력에 재분배한다. 종종 상관 스타일의 내적 행렬이 재가중 계수를 제공한다.
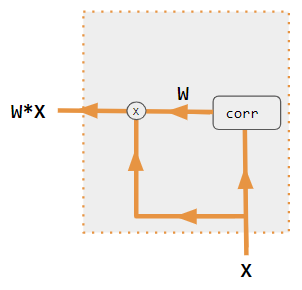
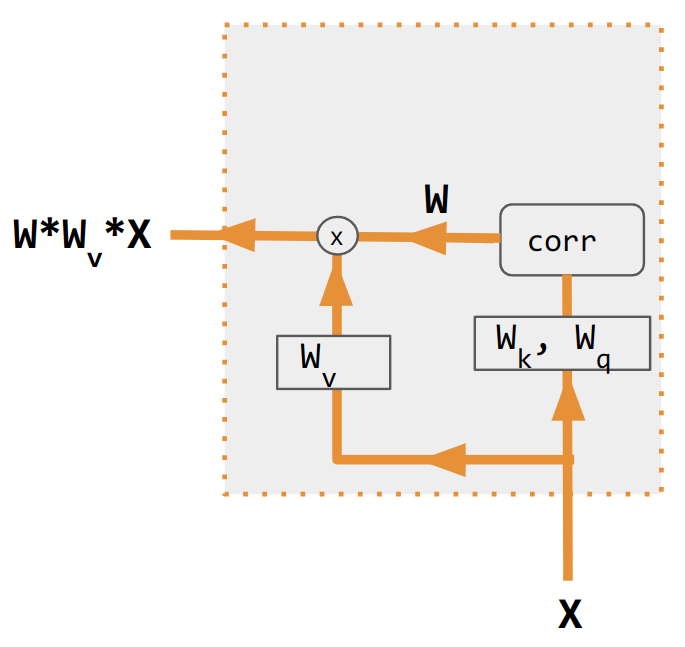
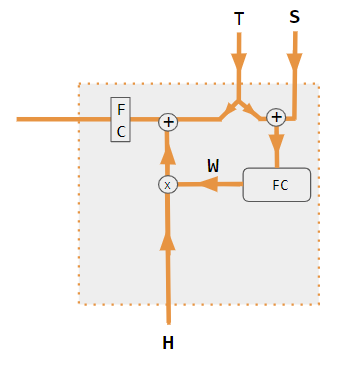
=== 가산 어텐션 (Additive Attention) ===
가산 어텐션(additive attention영어)은 Bahdanau 어텐션이라고도 불린다. 어텐션 가중치는 쿼리와 키 벡터를 연결하고, 학습 가능한 가중치 행렬과 tanh 함수를 사용하여 계산된다.[41]
=== 곱셈 어텐션 (Multiplicative Attention) ===
곱셈 어텐션(multiplicative attention영어)은 Luong attention영어이라고도 불린다. 쿼리와 키 벡터의 내적(dot product) 또는 일반적인 형태의 곱셈 연산을 사용하여 어텐션 가중치를 계산한다.
=== 셀프 어텐션 (Self-Attention) ===
셀프 어텐션(self-attention영어)은 쿼리, 키, 값 벡터가 모두 동일한 모델에서 나온다는 점을 제외하면 본질적으로 교차 어텐션과 동일하다. 인코더와 디코더 모두 셀프 어텐션을 사용할 수 있지만 미묘한 차이가 있다.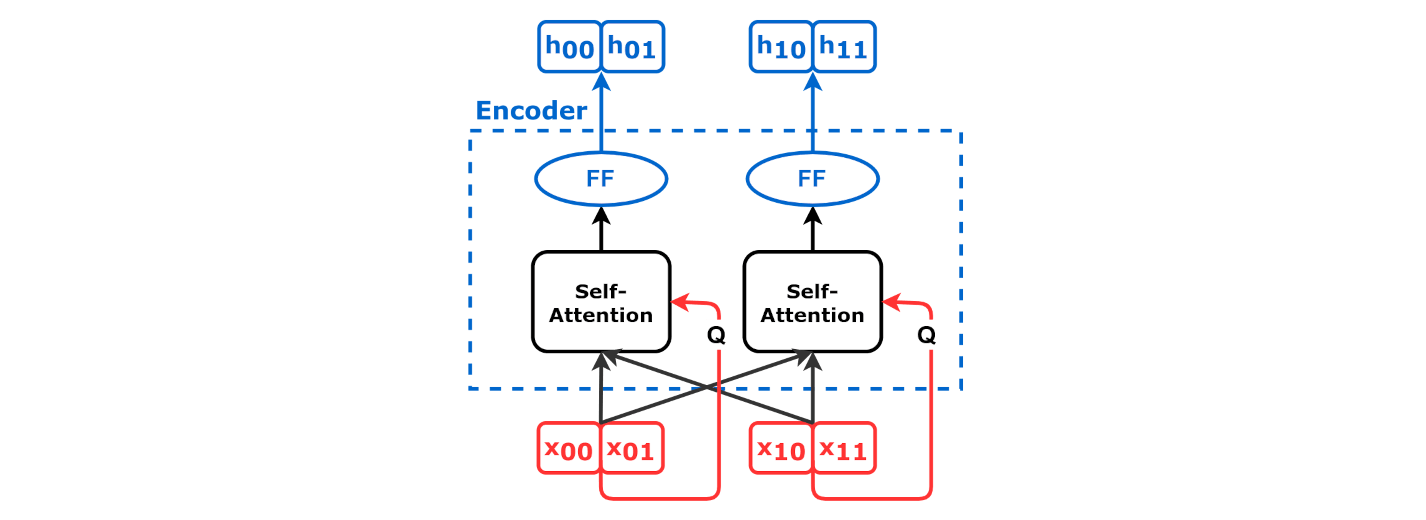
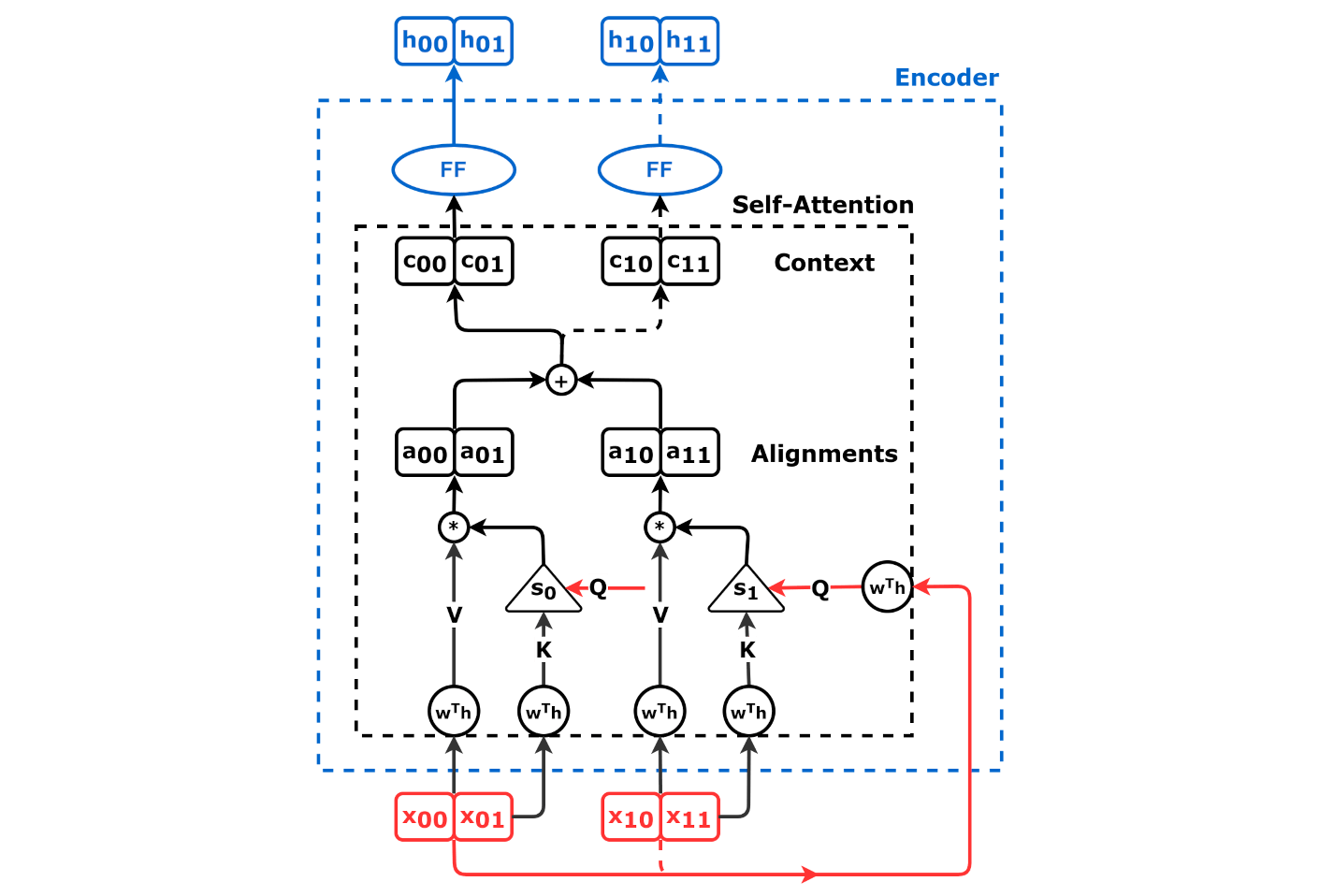
인코더 셀프 어텐션의 경우, 각 입력 단어를 고정된 lookup table(룩업 테이블)을 통해 벡터로 변환하는 "임베딩 레이어"와 같은 셀프 어텐션이 없는 간단한 인코더부터 시작할 수 있다. 입력 시퀀스 내의 각 요소 간의 관계를 모델링하는데 사용되며, 쿼리, 키, 값 벡터가 모두 동일한 입력 시퀀스에서 파생된다.
=== 멀티 헤드 어텐션 (Multi-Head Attention) ===
멀티 헤드 어텐션(Multi-Head Attention)은 여러 개의 어텐션 헤드를 사용하여 입력 시퀀스의 다양한 측면에 동시에 집중할 수 있도록 하는 기법이다. 각 헤드는 서로 다른 쿼리(Q), 키(K), 값(V) 변환을 학습한다.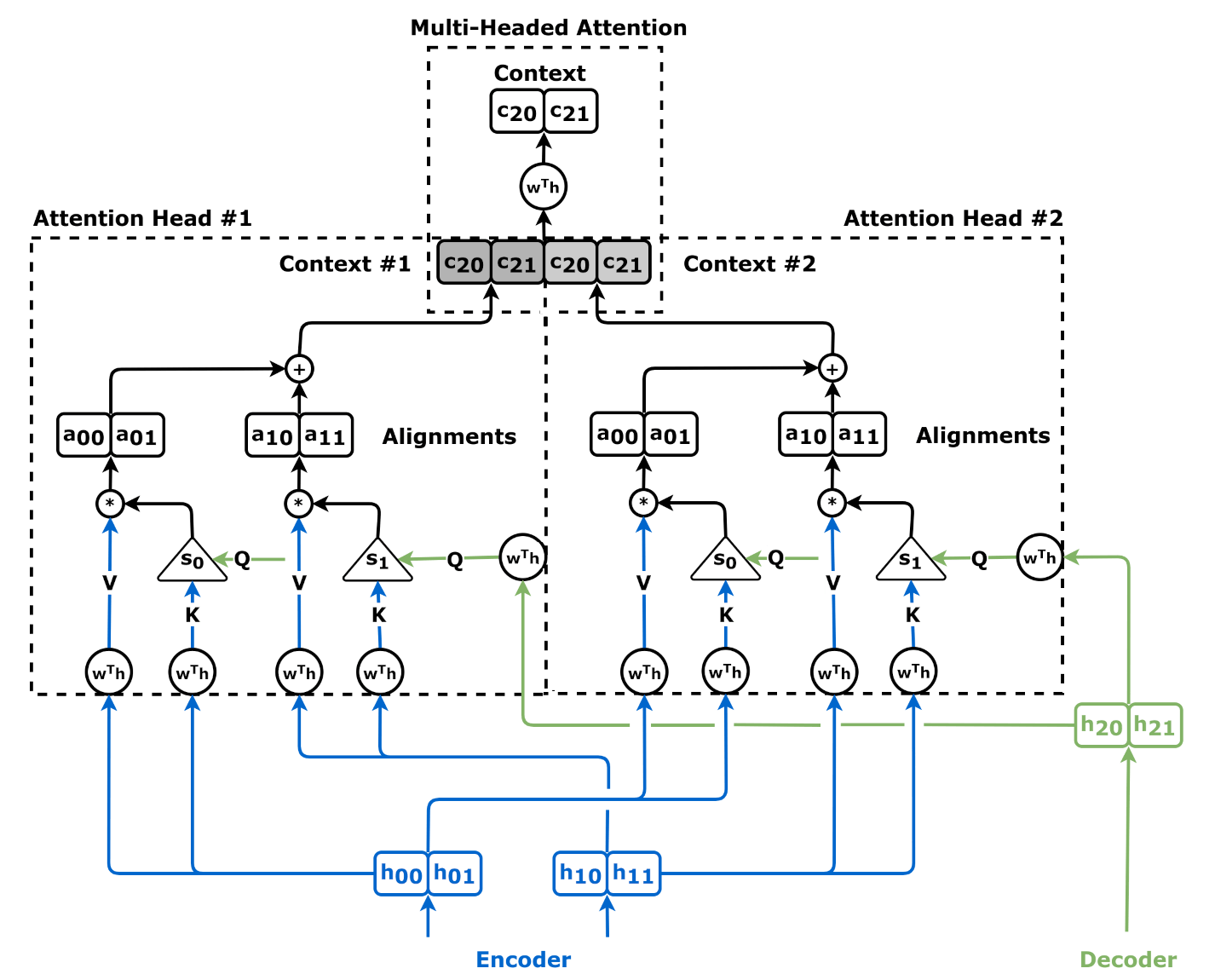
=== 마스크된 어텐션 (Masked Attention) ===
자기 회귀(autoregressive) 모델에서 미래 시점의 정보에 접근하는 것을 방지하기 위해 마스크된 어텐션이 사용된다. 어텐션 가중치 행렬의 상삼각 부분을 0으로 설정하여 마스킹을 수행한다.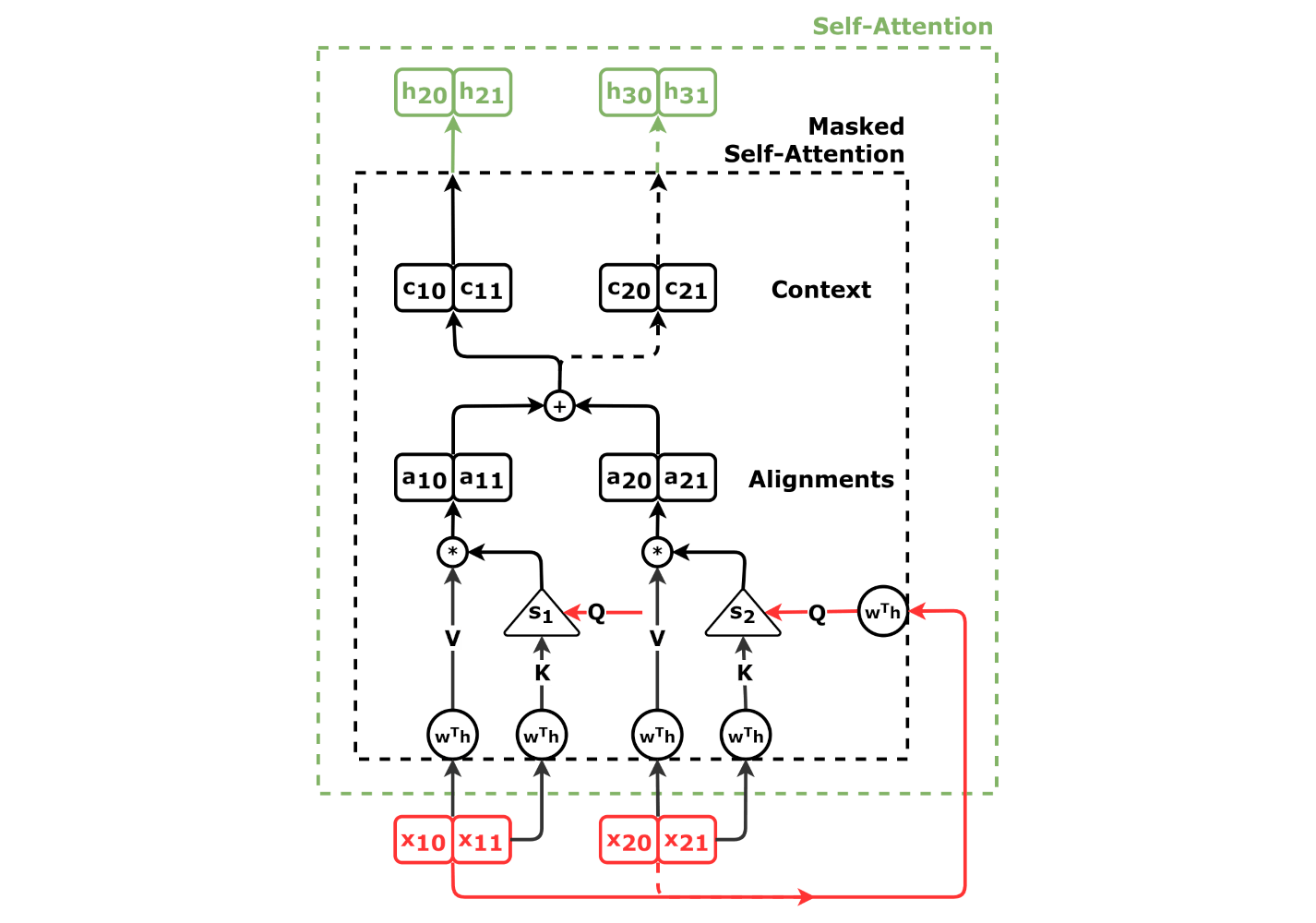
디코더 셀프-어텐션의 경우, 모든-대-모든 어텐션은 부적절하다. 자기 회귀적 디코딩 과정에서 디코더는 아직 디코딩되지 않은 미래의 출력에 어텐션할 수 없기 때문이다. 이는 "인과 마스킹"이라고 하는 모든 i < j 에 대해 어텐션 가중치 wij = 0 으로 강제함으로써 해결할 수 있다. 이 어텐션 메커니즘은 "인과 마스크된 셀프-어텐션"이다.
5. 1. 가산 어텐션 (Additive Attention)
가산 어텐션(additive attention영어)은 Bahdanau 어텐션이라고도 불린다. 어텐션 가중치는 쿼리와 키 벡터를 연결하고, 학습 가능한 가중치 행렬과 tanh 함수를 사용하여 계산된다.[41]여기서 이고, 와 는 학습 가능한 가중치 행렬이다.[41]
5. 2. 곱셈 어텐션 (Multiplicative Attention)
곱셈 어텐션(Multiplicative attention)은 Luong attention영어이라고도 불린다. 쿼리와 키 벡터의 내적(dot product) 또는 일반적인 형태의 곱셈 연산을 사용하여 어텐션 가중치를 계산한다.수식으로 표현하면 다음과 같다.
여기서 는 학습 가능한 가중치 행렬이다.[36]
5. 3. 셀프 어텐션 (Self-Attention)
셀프 어텐션(self-attention영어)은 쿼리, 키, 값 벡터가 모두 동일한 모델에서 나온다는 점을 제외하면 본질적으로 교차 어텐션과 동일하다. 인코더와 디코더 모두 셀프 어텐션을 사용할 수 있지만 미묘한 차이가 있다.인코더 셀프 어텐션의 경우, 각 입력 단어를 고정된 lookup table(룩업 테이블)을 통해 벡터로 변환하는 "임베딩 레이어"와 같은 셀프 어텐션이 없는 간단한 인코더부터 시작할 수 있다. 이렇게 하면 의 은닉 벡터 시퀀스가 생성된다. 그런 다음 이러한 벡터를 점곱 어텐션 메커니즘에 적용하여 다음을 얻는다.
:
더 간결하게는, 이다. 이를 반복적으로 적용하여 다층 인코더를 얻을 수 있다. 이것이 "인코더 셀프 어텐션"이며, 모든 위치의 벡터가 다른 모든 위치를 어텐션할 수 있으므로 때로는 "all-to-all attention"이라고도 한다. 입력 시퀀스 내의 각 요소 간의 관계를 모델링하는데 사용되며, 쿼리, 키, 값 벡터가 모두 동일한 입력 시퀀스에서 파생된다.
소프트웨어를 구현한 어텐션에는 다양한 변종이 존재한다. 예시로 다음과 같은 것들이 있다.
- 가산 어텐션(): 일명 Bahdanau Attention
- 곱셈 어텐션(): 일명 Luong Attention
- 셀프 어텐션()
합성곱 신경망의 경우, 어텐션 기구는 작용하는 차원, 즉 공간 어텐션, 채널 어텐션 또는 그 둘의 조합에 따라 구분할 수도 있다.
이러한 변종들은 인코더 측의 입력을 재배열하여 그 효과를 각 타겟 출력에 재분배한다. 많은 경우, 내적 상관 관계와 같은 행렬이 재가중 계수를 제공한다.
5. 4. 멀티 헤드 어텐션 (Multi-Head Attention)
멀티 헤드 어텐션(Multi-Head Attention)은 여러 개의 어텐션 헤드를 사용하여 입력 시퀀스의 다양한 측면에 동시에 집중할 수 있도록 하는 기법이다. 각 헤드는 서로 다른 쿼리(Q), 키(K), 값(V) 변환을 학습한다.각 는 QKV 어텐션을 사용하여 계산된다.
여기서 및 는 파라미터 행렬이다.
표준 QKV 어텐션의 순열 속성이 동일하게 적용된다. 순열 행렬 에 대해:
:
멀티 헤드 셀프 어텐션은 입력 행렬 의 행의 재정렬에 대해 등변량(equivariant)이다.
:
소프트웨어 구현에는 다양한 어텐션 변종이 존재하며, 그 예시는 다음과 같다.
- 가산 어텐션(additive attention영어): Bahdanau Attention이라고도 불린다.
- 곱셈 어텐션(multiplicative attention영어): Luong Attention이라고도 불린다.
- 셀프 어텐션(self-attention영어)
합성곱 신경망에서 어텐션 기구는 작용하는 차원에 따라 공간 어텐션, 채널 어텐션 또는 그 조합으로 구분할 수 있다.
5. 5. 마스크된 어텐션 (Masked Attention)
자기 회귀(autoregressive) 모델에서 미래 시점의 정보에 접근하는 것을 방지하기 위해 마스크된 어텐션이 사용된다. 어텐션 가중치 행렬의 상삼각 부분을 0으로 설정하여 마스킹을 수행한다.디코더 셀프-어텐션의 경우, 모든-대-모든 어텐션은 부적절하다. 자기 회귀적 디코딩 과정에서 디코더는 아직 디코딩되지 않은 미래의 출력에 어텐션할 수 없기 때문이다. 이는 "인과 마스킹"이라고 하는 모든 에 대해 어텐션 가중치 으로 강제함으로써 해결할 수 있다. 이 어텐션 메커니즘은 "인과 마스크된 셀프-어텐션"이다.
마스크드 어텐션의 수식은 다음과 같다.
:
여기서 마스크 는 엄격히 상 삼각 행렬로, 대각선 및 그 아래에는 0, 대각선 위의 모든 요소에는 가 있다. 소프트맥스 출력도 이며, 대각선 위의 모든 요소에 0이 있는 ''하 삼각 행렬''이다. 마스킹은 모든
6. 최적화
6. 1. 플래시 어텐션 (Flash Attention)
어텐션 행렬의 크기는 입력 토큰 수의 제곱에 비례한다. 따라서 입력이 길어지면 어텐션 행렬을 계산하는 데 많은 GPU 메모리가 필요하다. 플래시 어텐션(Flash Attention)은 정확도를 잃지 않으면서 메모리 요구 사항을 줄이고 효율성을 높이는 구현이다. 이는 어텐션 계산을 GPU의 더 빠른 온칩 메모리에 맞는 더 작은 블록으로 분할하여 대규모 중간 행렬을 저장할 필요성을 줄여 메모리 사용량을 줄이면서 계산 효율성을 높인다.[27]7. 활용
어텐션을 중심으로 하는 모델로 트랜스포머가 있다. 트랜스포머는 동일한 층 내에 여러 개의 독립적인 가중치 행렬을 갖는다. 트랜스포머는 기계 번역, 텍스트 요약, 질의응답 등 다양한 자연어 처리 작업에서 뛰어난 성능을 보인다.
트랜스포머의 스케일링 내적 어텐션, Perceiver/Perceiver영어에서는 쿼리・키・값(QKV)을 위한 어텐션이 사용된다.
7. 1. 트랜스포머 (Transformer)
어텐션을 중심으로 하는 모델로 트랜스포머가 있다. 트랜스포머는 동일한 층 내에 여러 개의 독립적인 가중치 행렬을 갖는다. 트랜스포머는 기계 번역, 텍스트 요약, 질의응답 등 다양한 자연어 처리 작업에서 뛰어난 성능을 보인다.트랜스포머의 스케일링 내적 어텐션, Perceiver/Perceiver영어에서는 쿼리・키・값(QKV)을 위한 어텐션이 사용된다.
7. 2. Perceiver
Perceiver는 이미지, 비디오, 오디오 등 다양한 모달리티의 데이터를 처리할 수 있는 어텐션 기반 모델이다. 쿼리・키・값(QKV)을 위한 어텐션을 사용한다.8. 한국어 처리에서의 어텐션
9. 수학적 표현
9. 1. 표준 스케일링 내적 어텐션 (Standard Scaled Dot-Product Attention)
표준 스케일링 내적 어텐션은 QKV 어텐션이라고도 불린다. Q는 쿼리 행렬, K는 키 행렬, V는 값 행렬을 의미하며, d_k는 키 벡터의 차원이다.행렬 \(\mathbf{Q}\in\mathbb{R^{m\times d_k}}, \mathbf{K}\in\mathbb{R^{n\times d_k}}\)와 \(\mathbf{V}\in\mathbb{R^{n\times d_v}}\)에 대해, 스케일링된 내적, 즉 QKV 어텐션은 다음과 같이 정의된다.
여기서 \({}^T\)는 전치를 나타내고, 소프트맥스 함수는 인수의 각 행에 독립적으로 적용된다. 행렬 \(\mathbf{Q}\)는 \(m\)개의 쿼리를 포함하고, 행렬 \(\mathbf{K}, \mathbf{V}\)는 공동으로 \(n\)개의 키-값 쌍의 "정렬되지 않은" 집합을 포함한다. 행렬 \(\mathbf{V}\)의 값 벡터는 소프트맥스 연산의 결과로 가중치가 부여되어, \(m\) x \(d_v\) 출력 행렬의 행이 \(\mathbb{R}^{d_v}\)의 점들의 볼록 껍질로 제한된다. 여기서 점들은 \(\mathbf{V}\)의 행으로 주어진다.
QKV 어텐션의 순열 불변성과 순열 등변성 속성을 이해하기 위해,[28] \(\mathbf{A}\in\mathbb{R}^{m\times m}\)와 \(\mathbf{B}\in\mathbb{R}^{n\times n}\)를 순열 행렬이라고 하고, \(\mathbf{D}\in\mathbb{R}^{m\times n}\)을 임의의 행렬이라고 하면, 소프트맥스 함수는 다음과 같은 순열 등변성을 가진다.
:
순열 행렬의 전치가 역행렬이기도 하다는 점을 고려하면 다음과 같다.
:
이는 QKV 어텐션이 쿼리( \(\mathbf{Q}\)의 행) 재정렬에 대해 등변이며, \(\mathbf{K},\mathbf{V}\)의 키-값 쌍 재정렬에 대해 불변임을 보여준다. 이러한 속성은 QKV 어텐션 블록의 입력 및 출력에 선형 변환을 적용할 때 상속된다. 예를 들어, 다음과 같이 정의된 간단한 셀프 어텐션 함수가 있다.
:
는 입력 행렬 \(X\)의 행을 재정렬하는 것에 대해 비자명한 방식으로 순열 등변성을 가지는데, 출력의 모든 행이 입력의 모든 행의 함수이기 때문이다. 유사한 속성은 ''멀티 헤드 어텐션''에도 적용된다.
표준 스케일링 내적 어텐션은 트랜스포머 및 에서 사용된다.
9. 2. 바흐다나우 어텐션 (Bahdanau Attention)
어텐션(Q, K, V)는 소프트맥스(e)V로 계산된다.[41] 여기서 e = tanh(W_QQ + W_KK)이며, W_Q와 W_K는 학습 가능한 가중치 행렬이다.[41]9. 3. 루옹 어텐션 (Luong Attention)
어텐션(Q, K, V) = 소프트맥스(QWaKT)V[36]여기서 Wa는 학습 가능한 가중치 행렬이다.[36]
참조
[1]
논문
A review on the attention mechanism of deep learning
https://www.scienced[...]
2021-09-10
[2]
논문
Attention mechanism in neural networks: where it comes and where it goes
https://link.springe[...]
2022-08
[3]
서적
Attention: From Theory to Practice
http://www.oxfordsch[...]
Oxford University Press
2006-12-28
[4]
논문
Some Experiments on the Recognition of Speech, with One and with Two Ears
http://www.ee.columb[...]
[5]
서적
Perception and Communication
Pergamon Press
[6]
논문
The role of attention in the programming of saccades
https://dx.doi.org/1[...]
1995-07-01
[7]
논문
Neural network model for selective attention in visual pattern recognition and associative recall
https://opg.optica.o[...]
1987-12-01
[8]
arXiv
Multiple Object Recognition with Visual Attention
2015-04-23
[9]
서적
Matters of Intelligence: Conceptual Structures in Cognitive Neuroscience
Springer Netherlands
2024-08-06
[10]
논문
A model of saliency-based visual attention for rapid scene analysis
https://ieeexplore.i[...]
1998-11
[11]
서적
Cybernetic Predicting Devices
"{{google books |pla[...]
CCM Information Corporation
[12]
서적
Cybernetics and forecasting techniques
"{{google books |pla[...]
American Elsevier Pub. Co.
[13]
arXiv
Annotated History of Modern AI and Deep Learning
2022
[14]
논문
Learning, invariance, and generalization in high-order neural networks
https://opg.optica.o[...]
1987-12-01
[15]
논문
Connectionist models and their properties
https://www.scienced[...]
1982-07-01
[16]
arXiv
HyperNetworks
2016-12-01
[17]
문서
Christoph von der Malsburg: The correlation theory of brain function. Internal Report 81-2, MPI Biophysical Chemistry, 1981. http://cogprints.org/1380/1/vdM_correlation.pdf See Reprint in Models of Neural Networks II, chapter 2, pages 95-119. Springer, Berlin, 1994.
[18]
문서
Jerome A. Feldman, "Dynamic connections in neural networks," Biological Cybernetics, vol. 46, no. 1, pp. 27-39, Dec. 1982.
[19]
논문
Using Fast Weights to Deblur Old Memories
https://escholarship[...]
1987
[20]
conference
Reducing the ratio between learning complexity and number of time-varying variables in fully recurrent nets
Springer
1993
[21]
arXiv
Sequence to sequence learning with neural networks
[22]
웹사이트
Show and Tell: A Neural Image Caption Generator
https://www.cv-found[...]
2015
[23]
논문
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
https://proceedings.[...]
PMLR
2015-06-01
[24]
arXiv
Neural Machine Translation by Jointly Learning to Align and Translate
2016-05-19
[25]
arXiv
Neural Turing Machines
2014-12-10
[26]
arXiv
Long Short-Term Memory-Networks for Machine Reading
2016-09-20
[27]
웹사이트
Flash Attention: Revolutionizing Transformer Efficiency
https://www.unite.ai[...]
2024-11-16
[28]
arXiv
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks
2018
[29]
웹사이트
Pytorch.org seq2seq tutorial
https://pytorch.org/[...]
2021-12-02
[30]
서적
Parallel Distributed Processing, Volume 1: Explorations in the Microstructure of Cognition: Foundations
MIT Press
1987-07-29
[31]
논문
Learning to control fast-weight memories: an alternative to recurrent nets.
1992
[32]
conference
Linear Transformers Are Secretly Fast Weight Programmers
Springer
2021
[33]
arXiv
Understanding Transformers via N-gram Statistics
2024
[34]
논문
Hybrid computing using a neural network with dynamic external memory
https://ora.ox.ac.uk[...]
2016-10-12
[35]
arXiv
Massive Exploration of Neural Machine Translation Architectures
2017-03-21
[36]
arXiv
Effective Approaches to Attention-Based Neural Machine Translation
2015-09-20
[37]
AV media
CS 152 NN—27: Attention: Keys, Queries, & Values
https://www.youtube.[...]
2021-12-22
[38]
AV media
NYU Deep Learning course, Spring 2020
https://www.youtube.[...]
2021-12-22
[39]
AV media
NYU Deep Learning course, Spring 2020
https://www.youtube.[...]
2021-12-22
[40]
웹사이트
NLP From Scratch: Translation With a Sequence To Sequence Network and Attention
https://pytorch.org/[...]
2021-12-22
[41]
arXiv
Neural Machine Translation by Jointly Learning to Align and Translate
2014
[42]
arXiv
CBAM: Convolutional Block Attention Module
2018-07-18
[43]
arXiv
Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution
2022-10-12
[44]
서적
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
[45]
서적
2019 IEEE/CVF International Conference on Computer Vision (ICCV)
[46]
서적
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
Association for Computational Linguistics
2016
[47]
웹사이트
Learning Positional Attention for Sequential Recommendation
https://www.catalyze[...]
[48]
저널
Trained Transformers Learn Linear Models In-Context
https://jmlr.org/pap[...]
2024
[49]
저널
Mapping of attention mechanisms to a generalized Potts model
[50]
arXiv
Simplifying Transformers Blocks
[51]
웹사이트
Transformer Circuits
https://transformer-[...]
[52]
arXiv
Learning the Greatest Common Divisor: Explaining Transformer Predictions
[53]
AV media
Transformer Neural Network Derived From Scratch
https://www.youtube.[...]
2024-04-07
[54]
문서
for mapping one ... sequence ... to another sequence ... Motivating our use of self-attention
[55]
문서
Motivating our use of self-attention ... Learning long-range dependencies is a key challenge in many sequence transduction tasks.
[56]
문서
for mapping one variable-length sequence ... Motivating our use of self-attention
[57]
문서
three desiderata ... Another is the amount of computation that can be parallelized
[58]
문서
A neural machine translation system ... translating a source sentence ... to a target sentence
[59]
문서
to encode a variable-length source sentence ... and to decode the vector into a variable-length target sentence
[60]
문서
A single convolutional layer ... does not connect all pairs of input and output positions. Doing so requires a stack of ... convolutional layers
[61]
문서
three desiderata ... The third is the path length between long-range dependencies in the network. ... One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network.
[62]
문서
An attention function can be described as mapping a query and a set of key-value pairs to an output
[63]
문서
An attention function ... The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
[64]
문서
We compute the dot products of the query with all keys, divide each by √ dk, and apply a softmax function
[65]
영상 인용
Deep Learning course at NYU, Spring 2020, video lecture Week 6
http://www.youtube.c[...]
2022-03-08
[66]
저널 인용
Learning to control fast-weight memories: an alternative to recurrent nets.
https://archive.org/[...]
1992
[67]
ArXiv 인용
Attention Is All You Need
2017-12-05
[68]
ArXiv 인용
Stand-Alone Self-Attention in Vision Models
2019-06-13
[69]
ArXiv 인용
Perceiver: General Perception with Iterative Attention
2021-06-22
[70]
웹인용
Google's Supermodel: DeepMind Perceiver is a step on the road to an AI machine that could process anything and everything
https://www.zdnet.co[...]
2021-08-19
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com